2023年5月,聯發科與英偉達宣布合作,共同研發車載芯片,原本計劃是采用Chiplet形式。
2024年3月,聯發科正式發布新一代Dimensity Auto 座艙平臺,最大亮點是英偉達RTX GPU IP的加入和臺積電3納米的制造工藝。臺積電3納米制造工藝是目前芯片行業最先進的制造工藝,這是汽車芯片第一次與手機和AI芯片同時使用最先進的制造工藝,但不是Chiplet,推測一來是3納米的Chiplet制造工藝不夠成熟,二就是Chiplet需要動用臺積電先進封裝,成本并不比單一die低,甚至可能高2-3倍,汽車行業對價格還是相對比較敏感的。
聯發科是一家非常低調的公司,品牌形象營造遠不如高通,也極少對外透露信息。

聯發科一直被高通擠壓,特別是在GPU和AI方面,聯發科引入英偉達的GPU IP來彌補這一短板。
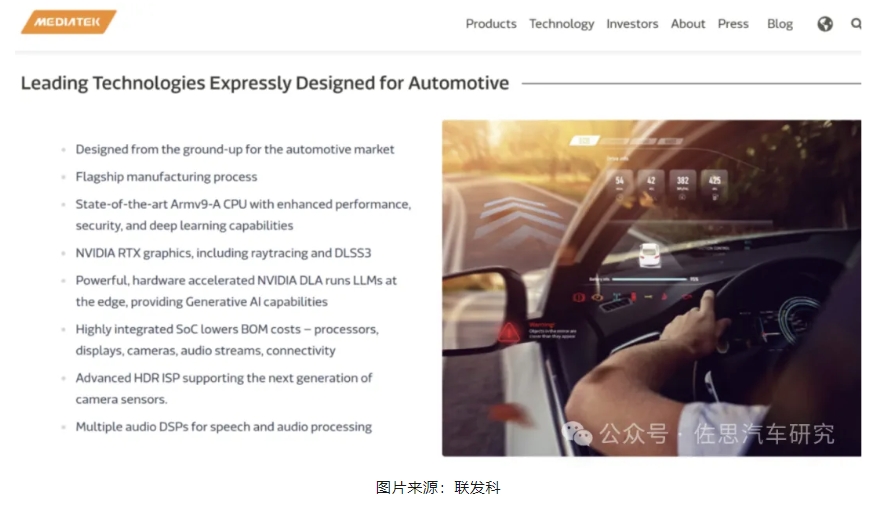
從聯發科官方介紹中,我們不難看出聯發科使用的英偉達GPU IP是何種類型的IP,因為DLSS3是RTX40系列獨有的功能,也就是說聯發科使用了英偉達RTX40系列桌面顯卡的IP。

簡單介紹一下DLSS3
 DLSS全稱Deep Learning Super Sampling(深度學習超采樣),主要包括DLAA、插幀和光線重建。插幀即幀生成,它可以生成全新幀,而不僅是像素,從而帶來驚人的性能提升。基于NVIDIA® Ada Lovelace架構的新光流加速器可分析兩幀連續的游戲圖像,并計算幀到幀中物體和元素的運動矢量數據,而不使用傳統游戲引擎的運動矢量進行建模。這極大地減少了AI在渲染諸如粒子、反射、陰影和光照等元素時的視覺異常。通過綜合游戲中的一對超級分辨率幀,以及引擎和光流運動矢量,并將其輸入至卷積神經網絡,就能計算生成出新的一幀,這在實時游戲渲染中是首次實現。將DLSS生成的全新幀與DLSS超級分辨率幀相結合,使DLSS 3能用AI重建八分之七的顯示像素,與沒有DLSS相比,游戲性能提升了4倍。
由于DLSS生成幀在GPU上作為后處理執行,即使游戲受到CPU性能限制,也能從中獲得游戲性能提升。對于受到CPU限制的游戲,例如物理計算密集型游戲或大型場景游戲,DLSS 3令GeForce RTX® 40系列GPU以高達兩倍于CPU可計算的性能渲染游戲。
DLSS 3集成也包括NVIDIA Reflex,可以使GPU和CPU同步,確保最佳響應速度和低系統延遲。
DLSS3的插幀技術目前還是英偉達獨有,AMD和英特爾沒有,也就是說如果用聯發科的芯片運行《賽博朋克2077》這樣的硬件殺手游戲,效果或可以碾壓特斯拉座艙的AMD 分離式GPU。
RTX40系列也有多個版本,最低的是筆記本電腦用的GTX4050,AD107架構,2560個CUDA,聯發科最大可能用這個架構。RTX4050的稀疏INT8算力估計有104TOPS,將來聯發科的旗艦芯片或許AI算力大約就是100TOPS,當然了功耗會有25-35瓦以上,水冷恐怕不可避免。
另一大特色就是3納米工藝,據稱目前蘋果和聯發科已經包下了臺積電全部的3納米產能,高通拿不到臺積電的3納米產能了,高通打算使用三星的3納米。眾所周知,三星與臺積電差距還是很大的。制造工藝上,聯發科與同在臺灣省內的臺積電合作更加順利,聯發科的手機芯片也拿到了4納米首發,領先了高通一步,3納米上基本也可以確定,聯發科也是首發。臺積電第一代3nm工藝是N3B,由臺積電的大客戶蘋果率先使用,A17 Pro、M3系列芯片等都是使用的臺積電第一代3nm工藝制程。臺積電第二代3nm工藝是N3E,N3E預計將比N3B應用更廣泛,除了前面提到的聯發科天璣9400芯片外,高通驍龍8 Gen4、A18系列芯片也原本計劃采用N3E工藝。臺積電N3E是N3B的增強版,良率更高,成本更低,但密度會略低于N3B。
聯發科這次也是和高通一樣,手機芯片與車載芯片同步,都采用最先進的3納米制造工藝,考慮到3納米高達數億美元的驚人的一次性流片成本,聯發科的手機和車載芯片應該有共通之處。
2023年9月,聯發科宣布首款使用臺積電3納米工藝的芯片即將在2024年量產,這就是聯發科新旗艦天璣9400。
天璣9300開始使用全大核設計,晶體管數量高達227億,比英偉達自動駕駛Orin的170億還要多很多。天璣9300的227億晶體管,是真正的遙遙領先:蘋果A16是160億,A17 Pro是190億,蘋果M2是200億。即便是蘋果M3,也“僅”有250億晶體管,而高通好幾代沒公布晶體管數目了。歷史性的取消小核,CPU由4顆X4超大核和4顆A720大核組成,最高頻的X4有更大的緩存。跳出安卓SoC的視角看,天璣9300的4顆超大核和4顆大核,其實更接近于蘋果A系列和英特爾的P核(性能核)、E核(能效核)概念。
天璣首發LPDDR5T 9600Mbps內存,速度比之前的LPDDR5x 8533Mbps提升12.5%,這是大家以為要等LPDDR6才能達到的頻率(2年前的天璣9000是首發LPDDR 5x 7500Mbps內存,天璣9200是首發LPDDR5x 8533Mbps)。
天璣9400采用ARM旗艦Cortex-x5(下圖TCS24就是Cortex-x5,代號黑鷹),這是ARM最強CPU架構。
DLSS全稱Deep Learning Super Sampling(深度學習超采樣),主要包括DLAA、插幀和光線重建。插幀即幀生成,它可以生成全新幀,而不僅是像素,從而帶來驚人的性能提升。基于NVIDIA® Ada Lovelace架構的新光流加速器可分析兩幀連續的游戲圖像,并計算幀到幀中物體和元素的運動矢量數據,而不使用傳統游戲引擎的運動矢量進行建模。這極大地減少了AI在渲染諸如粒子、反射、陰影和光照等元素時的視覺異常。通過綜合游戲中的一對超級分辨率幀,以及引擎和光流運動矢量,并將其輸入至卷積神經網絡,就能計算生成出新的一幀,這在實時游戲渲染中是首次實現。將DLSS生成的全新幀與DLSS超級分辨率幀相結合,使DLSS 3能用AI重建八分之七的顯示像素,與沒有DLSS相比,游戲性能提升了4倍。
由于DLSS生成幀在GPU上作為后處理執行,即使游戲受到CPU性能限制,也能從中獲得游戲性能提升。對于受到CPU限制的游戲,例如物理計算密集型游戲或大型場景游戲,DLSS 3令GeForce RTX® 40系列GPU以高達兩倍于CPU可計算的性能渲染游戲。
DLSS 3集成也包括NVIDIA Reflex,可以使GPU和CPU同步,確保最佳響應速度和低系統延遲。
DLSS3的插幀技術目前還是英偉達獨有,AMD和英特爾沒有,也就是說如果用聯發科的芯片運行《賽博朋克2077》這樣的硬件殺手游戲,效果或可以碾壓特斯拉座艙的AMD 分離式GPU。
RTX40系列也有多個版本,最低的是筆記本電腦用的GTX4050,AD107架構,2560個CUDA,聯發科最大可能用這個架構。RTX4050的稀疏INT8算力估計有104TOPS,將來聯發科的旗艦芯片或許AI算力大約就是100TOPS,當然了功耗會有25-35瓦以上,水冷恐怕不可避免。
另一大特色就是3納米工藝,據稱目前蘋果和聯發科已經包下了臺積電全部的3納米產能,高通拿不到臺積電的3納米產能了,高通打算使用三星的3納米。眾所周知,三星與臺積電差距還是很大的。制造工藝上,聯發科與同在臺灣省內的臺積電合作更加順利,聯發科的手機芯片也拿到了4納米首發,領先了高通一步,3納米上基本也可以確定,聯發科也是首發。臺積電第一代3nm工藝是N3B,由臺積電的大客戶蘋果率先使用,A17 Pro、M3系列芯片等都是使用的臺積電第一代3nm工藝制程。臺積電第二代3nm工藝是N3E,N3E預計將比N3B應用更廣泛,除了前面提到的聯發科天璣9400芯片外,高通驍龍8 Gen4、A18系列芯片也原本計劃采用N3E工藝。臺積電N3E是N3B的增強版,良率更高,成本更低,但密度會略低于N3B。
聯發科這次也是和高通一樣,手機芯片與車載芯片同步,都采用最先進的3納米制造工藝,考慮到3納米高達數億美元的驚人的一次性流片成本,聯發科的手機和車載芯片應該有共通之處。
2023年9月,聯發科宣布首款使用臺積電3納米工藝的芯片即將在2024年量產,這就是聯發科新旗艦天璣9400。
天璣9300開始使用全大核設計,晶體管數量高達227億,比英偉達自動駕駛Orin的170億還要多很多。天璣9300的227億晶體管,是真正的遙遙領先:蘋果A16是160億,A17 Pro是190億,蘋果M2是200億。即便是蘋果M3,也“僅”有250億晶體管,而高通好幾代沒公布晶體管數目了。歷史性的取消小核,CPU由4顆X4超大核和4顆A720大核組成,最高頻的X4有更大的緩存。跳出安卓SoC的視角看,天璣9300的4顆超大核和4顆大核,其實更接近于蘋果A系列和英特爾的P核(性能核)、E核(能效核)概念。
天璣首發LPDDR5T 9600Mbps內存,速度比之前的LPDDR5x 8533Mbps提升12.5%,這是大家以為要等LPDDR6才能達到的頻率(2年前的天璣9000是首發LPDDR 5x 7500Mbps內存,天璣9200是首發LPDDR5x 8533Mbps)。
天璣9400采用ARM旗艦Cortex-x5(下圖TCS24就是Cortex-x5,代號黑鷹),這是ARM最強CPU架構。
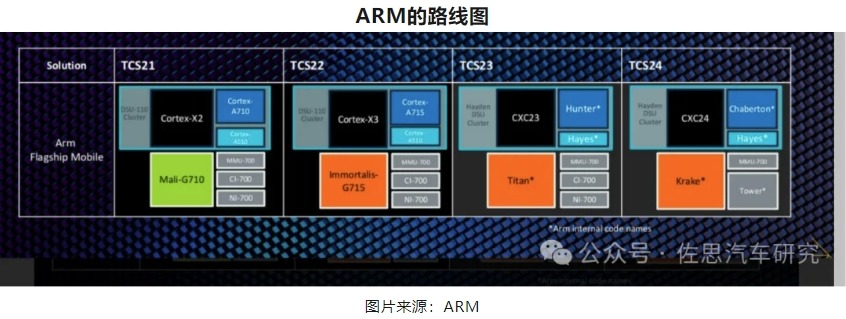
Cortex-x5據說將消除Arm設計的CPU內核與蘋果基于Arm指令集自研的CPU內核之間的性能差距。Moor Insights & Strategy CEO Patrick Moorhead指出,ARM全新的Cortex-X系列CPU內核的內部代號為“Blackhawk”,是ARM CEO Rene Haas接下來的工作重點之一,旨在消除Arm設計的CPU內核與蘋果基于Arm指令集自研的CPU內核之間的性能差距。Moorhead引用ARM說法表示,“Blackhawk”核心將會帶來巨大的性能提升,是五年來同比最大的IPC性能提升。
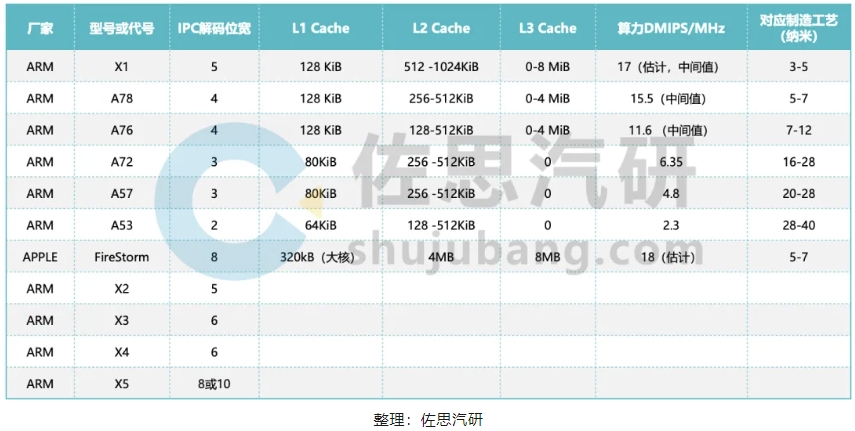 多年來ARM一直在擠牙膏,IPC帶寬從2位,緩慢上升,而蘋果一開始就到巔峰的8位,導致安卓性能遠低于蘋果,X5可能追平蘋果的8位解碼寬度,也可能直接到10位,超過蘋果。
多年來ARM一直在擠牙膏,IPC帶寬從2位,緩慢上升,而蘋果一開始就到巔峰的8位,導致安卓性能遠低于蘋果,X5可能追平蘋果的8位解碼寬度,也可能直接到10位,超過蘋果。
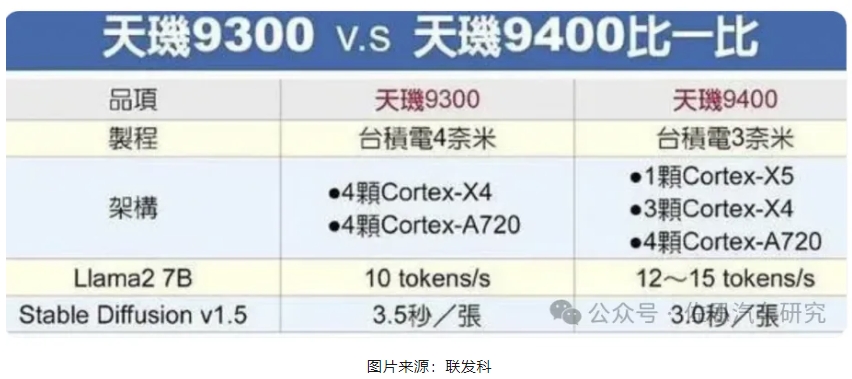
很多人以為AI運算和CPU沒關系,或者說CPU無法做AI運算,實際上CPU完全可以做任何類型的AI運算,只是數據吞吐能力不如GPU或AI加速器,拋開數據吞吐,單純AI運算,CPU是最快的。ARM最新的CPU如Cortex-X3/X4/X5,都能夠運行大模型,目前手機領域或者說移動領域大模型最常見的是LIama2,這是目前最好的語言類開源大模型。天璣9400可以做到每秒12-15 tokens。
簡單介紹一下LIama2,Meta 出品的 Llama 續作 Llama2,一系列模型(7B、13B、70B)均開源可免費商用。Llama2在各個榜單上精度全面超過Llama1,同時也超過目前所有開源模型。用于車載和手機的70億參數的相對較小的模型。
盡管語言類大模型LLM訓練方法很直觀:基于自回歸的transformer模型,在大量預料上做自監督訓練,然后通過人類反饋強化學習 (RLHF) 等技術來與人類偏好對齊。但高計算需求限制了LLM 只能由少數玩家來推動發展。現有的開源大模型,例如BLOOM、Llama1、Falcon,雖然都能基本達到匹配非開源大模型(如GPT-3、Chinchilla)的能力,但這些模型都不適合成為非開源產品級LLM (比如ChatGPT、BARD、Claude)的替代品,因為這些封閉的產品級LLM經過大量微調,與人類的偏好保持一致,大大提高了它們的可用性和安全性。這一步在計算和人工標注中需要大量的成本,而且往往不透明或容易重現,限制了社區的進步,以促進AI對齊研究。
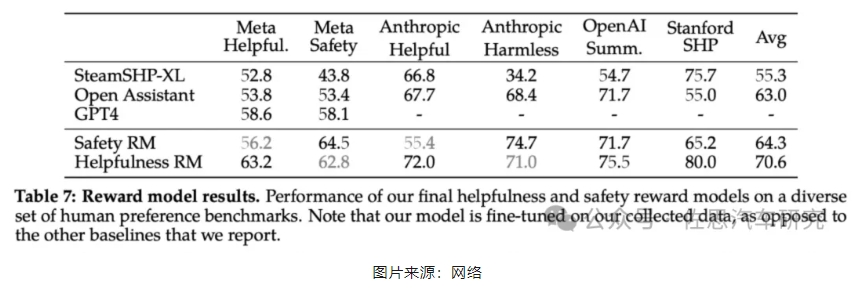
Meta自己的獎勵模型在基于Llama 2-Chat收集的內部測試集上表現最佳,其中「有用性」獎勵模型在「元有用性」測試集上表現最佳,同樣,「安全性」獎勵模型在「元安全性」測試集上表現最佳。總體而言,Meta的獎勵模型優于包括GPT-4在內的所有基線模型。有趣的是,盡管GPT-4 沒有經過直接訓練,也沒有專門針對這一獎勵建模任務,但它的表現卻優于其他非元獎勵模型。
聯發科是下了與高通、AMD決戰的勇氣,但在品牌宣傳上是不是也太落后了?!
免責說明:本文觀點和數據僅供參考,和實際情況可能存在偏差。本文不構成投資建議,文中所有觀點、數據僅代表筆者立場,不具有任何指導、投資和決策意見。



 首頁
首頁 2024.03.27
2024.03.27
 周彥武
周彥武